| | | |
 Was ist ein Wissensnetz? Was ist ein Wissensnetz?
Was
ist ein Wissensnetz? In einem Wissensnetz werden Themen und Objekte des Geschäfts
miteinander verknüpft und so eine Schicht Semantik über den Daten und
Dokumenten eines Unternehmens etabliert. Objekte des Wissensnetzes sind
beispielsweise Firmen, Mitarbeiter, Produkte, Projekte, Technologien etc. Relationen
verbinden diese Objekte: Mitarbeiter sind mit der Relation „leitet”
oder „arbeitet mit in” mit Projekten verbunden, sind aber auch Abteilungen
zugeordnet. Projekte werden „durchgeführt im Auftrag” von Kunden
und „nutzen” Technologien. Technologien werden wiederum über die
Ober-/Unterbegriffsrelation in Technologiebereiche gegliedert. In den meisten
Fällen enthält das Wissensnetz Fakten aus strukturierten Datenquellen
wie Produkt- oder Kundendatenbanken. Zusätzlich werden sehr oft Dokumente
und Know-how-Träger in diese Zusammenhänge eingeordnet – auf diese
Weise entsteht ein intelligentes Verzeichnis aller Wissensressourcen im Unternehmen.
Wissensnetze kombinieren die Intelligenz von Wissensrepräsentationen der
KI-Forschung mit den pragmatischen Anforderungen des Unternehmensalltags. Ist
ein Wissensnetz eine Datenbank? Wissensnetze können insofern als Datenbanken
verstanden werden, als sie strukturierte Informationen persistent speichern und
zugänglich machen. Darüber hinaus bieten sie aber spezielle Unterstützung
für die Wissensarbeit: - Wissensnetze zeichnen sich durch eine hohe
Flexibilität im Schema aus; auch komplexe Sachverhalte können sehr einfach
und gleichzeitig differenziert festgehalten werden. Änderungen im Schema
sind ebenfalls wesentlich leichter zu realisieren als im Schema einer relationalen
Datenbank.
- Wissensnetze eignen sich zur Repräsentation strukturierter
Fakten ebenso gut wie zur Abbildung von Themen und ihrer Zusammenhänge. So
können sie operative Daten und Taxonomien zusammenbringen.
- Die DJUB-Wissensnetze
liefern eine Fülle von nützlichen Suchfunktionen, Navigationsmöglichkeiten
und Sichten, weitere können sehr leicht ergänzt werden. Dies verkürzt
die Zeit erheblich, die für die Anwendungsentwicklung benötigt wird.
- Die
Logik von Themen und Unterthemen, ihren Verknüpfungen etc. ist im Schema
bereits eingebaut, genauso wie die Mechanismen zum automatischen Schlussfolgern.
- Schließlich
eignen sich Wissensnetze hervorragend zur Erschließung von Dokumenten.
Was
ist der Unterschied zu einer Suchmaschine? Suchmaschinen vergleichen die Eingabe
des Nutzers mit einem Bestand an Dokumenten. Ein Dokument wird dann als Treffer
an den Nutzer zurückgeliefert, wenn exakt die (Teil-)Zeichenkette, die eingegeben
wurde, im Text des Dokuments vorkommt. Fortgeschrittene Produkte bringen, z.B.
mit statistischen Verfahren, ein Minimum an Unschärfe in den Vergleich ein
– die Basis bleibt aber auch hier ein Vergleich von Zeichenketten. Daher
muss der Suchende Prognosen darüber treffen, welche Worte in welcher Schreibweise
denn wahrscheinlich in relevanten Dokumenten vorkommen. Dies führt sehr oft
zu einer großen Anzahl irrelevanter Treffer und – schwerwiegender noch
– dazu, dass viele relevante Dokumente nicht gefunden werden, weil sie statt
des Suchbegriffs eine Umschreibung, ein Synonym oder einen allgemeineren Begriff
enthalten.
Eine größere Unabhängigkeit von den Formulierungen
in den Texten können nur semantische Technologien bieten. Suchmaschinen erlauben
einen Zugriff auf ansonsten unüberschaubare Mengen von Information. Sie operieren
ohne Vorwissen über den Kontext der Suche: Wer z.B. sucht Informationen zu
welchem Zweck, was geschieht mit den Suchergebnissen etc.? Wenn die Suche aber
in Geschäftsprozesse verankert, mit Navigation/Exploration kombiniert, in
einen aktiven Information Push umgewandelt werden soll oder wenn außer Dokumenten
z.B. auch Experten als Treffer zurückgeliefert werden sollen, wenn strukturierte
Informationen in die Suche einbezogen werden sollen, dann stoßen Suchmaschinen
an ihre Grenzen. Ein umfassenderer Zugang zu unternehmenskritischer Information
ist die Domäne von Wissensnetzen. Wo kommt das Wissensnetz her?
Welcher Aufwand ist mit seinem Aufbau verbunden? Ein Großteil der Informationen,
die ein Wissensnetz ausmachen, kommt aus bereits existierenden Quellen. Allein
durch die Integration von Informationen, die zwar alle schon strukturiert vorliegen,
die aber in einem Wissensnetz erstmals zusammenkommen, verbunden mit der Möglichkeit,
quer über verschiedene Informationstypen und Quellen zu suchen, wird ein
großer Mehrwert geschaffen. Auf der anderen Seite ist das bedarfsgerechte
Strukturieren von Information eine intellektuelle Arbeit. Oft kommen zusätzliche
Informationen oder Verknüpfungen hinzu, die sich bisher in keiner Datenquelle
finden. Daher ist durchaus manueller Aufwand mit dem Aufbau eines Wissensnetzes
verbunden. Das macht die einfachen Möglichkeiten des Aufbaus und der Pflege
so wichtig. Quellen, die typischerweise in ein Wissensnetz einfließen, sind
Kunden- und Produktdatenbanken wie auch Verzeichnisse von Mitarbeitern und Organisationseinheiten.
Oft liegen unternehmensinterne oder branchenweite Glossare und Taxonomien vor,
ein wertvoller Input kann aber auch schon die Verzeichnisstruktur eines Laufwerks
sein. Externe Datenquellen können fest oder dynamisch eingebunden
werden, das führende System kann das Wissensnetz sein oder die vorliegende
Datenbank. Bei der intellektuellen manuellen Pflege unterscheiden wir zwischen
zentraler Strukturierung – die möglichen Objekttypen und Verknüpfungen,
aber auch Themen werden meist zentral vorgegeben – und dezentraler Eingabe,
z.B. von Projekten, Kundenkontakten usw. durch den einzelnen Nutzer. Diese geschieht
über sehr einfache Pflegemasken, die in die Rechercheoberfläche eingebunden
sind.
| |  Straßenmaler 2001 in Geldern
Straßenmaler 2001 in Geldern
| |
 | Broschüre
>> |
 |
| | | | Einsatzgebiete
>> | |
| | | | Unternehmen
die solche Lösungen einsetzen | |
| | Thyssenkrupp
Brockhaus AG
Süddeutscher Verlag
Union
Investment
Tomorrow Focus AG | | | | | | |

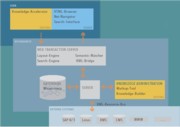
Grundprinzip
Architektur
|